Chapter 7 Understanding distributions
Large survey datasets contain many variables and many observations. To learn from such data, you need tools that summarise patterns clearly and accurately. This chapter introduces distributions—the way a variable’s values are spread across the sample—and shows how to describe distributions using tables, summary statistics, and simple plots. Because the ICAN-ICAR data come from a complex survey, we also show how to produce weighted summaries that reflect the target population.
7.1 Getting oriented to the data
Firstly, check the number of rows and columns to get a sense of how big the data.
## [1] 96452 147This is quite big. A plausible idea from here is to subset to the variables that we want to explore. This will largely depend on what we want to answer. The dplyr package has a select function that allows one to select and rearrange variables. For this session, we focus only on the child’s age, parents’ age, eyesight,school type, enrollment status, and whether or not the child has met the minimum proficiency level for both numeracy and literacy.
dat = dat |>
select(CountryName, Location, HHID,VillageID, ChildID, TierOneUnit,
ch02, ch06a, ch06b, EnrolmentStatus, pt02b, ch03,hh07a,
pt01b, ch04a, MPLBoth, HHWeightProvided) One can use the skim() function from skimr package to attain a broad view of the data and get useful summary statistics on each variable. It is useful because it handles data of all types and it is an alternative to summary(). We focus only on enrolled children
| Name | filter(dat, EnrolmentStat… |
| Number of rows | 84396 |
| Number of columns | 17 |
| _______________________ | |
| Column type frequency: | |
| character | 7 |
| numeric | 10 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| CountryName | 0 | 1 | 4 | 10 | 0 | 11 | 0 |
| Location | 0 | 1 | 5 | 5 | 0 | 2 | 0 |
| HHID | 0 | 1 | 41 | 41 | 0 | 52996 | 0 |
| VillageID | 0 | 1 | 4 | 4 | 0 | 624 | 0 |
| ChildID | 0 | 1 | 48 | 66 | 0 | 84396 | 0 |
| TierOneUnit | 0 | 1 | 4 | 4 | 0 | 121 | 0 |
| EnrolmentStatus | 0 | 1 | 18 | 18 | 0 | 1 | 0 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| ch02 | 0 | 1.0000000000000000000000 | 10.1400000000000005684342 | 3.1499999999999999111822 | 5.0000000000000000000000 | 8.0000000000000000000 | 10.000000000000000000 | 13.000000000000000000 | 16.00000000000000000 | ▇▆▆▆▆ |
| ch06a | 171 | 1.0000000000000000000000 | 4.0700000000000002842171 | 2.8700000000000001065814 | 0.0000000000000000000000 | 2.0000000000000000000 | 4.000000000000000000 | 6.000000000000000000 | 12.00000000000000000 | ▇▅▆▂▁ |
| ch06b | 171 | 1.0000000000000000000000 | 1.2900000000000000355271 | 0.5200000000000000177636 | 1.0000000000000000000000 | 1.0000000000000000000 | 1.000000000000000000 | 2.000000000000000000 | 3.00000000000000000 | ▇▁▂▁▁ |
| pt02b | 28414 | 0.6600000000000000310862 | 42.7999999999999971578291 | 9.4000000000000003552714 | 18.0000000000000000000000 | 36.0000000000000000000 | 42.000000000000000000 | 48.000000000000000000 | 80.00000000000000000 | ▁▇▆▁▁ |
| ch03 | 0 | 1.0000000000000000000000 | 1.4899999999999999911182 | 0.5000000000000000000000 | 1.0000000000000000000000 | 1.0000000000000000000 | 1.000000000000000000 | 2.000000000000000000 | 2.00000000000000000 | ▇▁▁▁▇ |
| hh07a | 0 | 1.0000000000000000000000 | 2.1800000000000001598721 | 0.4500000000000000111022 | 1.0000000000000000000000 | 2.0000000000000000000 | 2.000000000000000000 | 2.000000000000000000 | 3.00000000000000000 | ▁▁▇▁▂ |
| pt01b | 12297 | 0.8499999999999999777955 | 36.1799999999999997157829 | 7.9000000000000003552714 | 18.0000000000000000000000 | 30.0000000000000000000 | 35.000000000000000000 | 40.000000000000000000 | 80.00000000000000000 | ▃▇▂▁▁ |
| ch04a | 0 | 1.0000000000000000000000 | 1.0400000000000000355271 | 0.2200000000000000011102 | 1.0000000000000000000000 | 1.0000000000000000000 | 1.000000000000000000 | 1.000000000000000000 | 4.00000000000000000 | ▇▁▁▁▁ |
| MPLBoth | 5000 | 0.9399999999999999467093 | 0.3099999999999999977796 | 0.4600000000000000199840 | 0.0000000000000000000000 | 0.0000000000000000000 | 0.000000000000000000 | 1.000000000000000000 | 1.00000000000000000 | ▇▁▁▁▃ |
| HHWeightProvided | 0 | 1.0000000000000000000000 | 3277.9600000000000363797881 | 3883.9000000000000909494702 | 0.4199999999999999844569 | 665.6299999999999954525 | 2285.400000000000090949 | 4056.590000000000145519 | 57152.22000000000116415 | ▇▁▁▁▁ |
complete_rate tells us the proportion of rows that are not missing for that particular variable. For instance, pt02b has only \(55\%\) of rows that have entries. n_unique counts the number of unique categories or values in a particular variable, i.e., there is only two categories (Urban and Rural) in Location.
To customize the summaries we want to see we can use skim_with alongside the sfl() helper function. For now, let us see only the numeric variables and show only the mean, sd, interquartile range, and the median of each variable.
# create your own skimmer
my_skim = skim_with(numeric = sfl(p0 = NULL, p100 = NULL,
p25=NULL, p75 = NULL,
hist = NULL,
iqr = ~IQR(., na.rm = TRUE)))
# then skim
dat |>
my_skim()| Name | dat |
| Number of rows | 96452 |
| Number of columns | 17 |
| _______________________ | |
| Column type frequency: | |
| character | 7 |
| numeric | 10 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| CountryName | 0 | 1 | 4 | 10 | 0 | 11 | 0 |
| Location | 0 | 1 | 5 | 5 | 0 | 2 | 0 |
| HHID | 0 | 1 | 41 | 41 | 0 | 56880 | 0 |
| VillageID | 0 | 1 | 4 | 4 | 0 | 627 | 0 |
| ChildID | 0 | 1 | 48 | 66 | 0 | 96452 | 0 |
| TierOneUnit | 0 | 1 | 4 | 4 | 0 | 121 | 0 |
| EnrolmentStatus | 0 | 1 | 13 | 18 | 0 | 3 | 0 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p50 | iqr |
|---|---|---|---|---|---|---|
| ch02 | 0 | 1.0000000000000000000000 | 10.000000000000000000000 | 3.2500000000000000000000 | 10.000000000000000000 | 6.000000000000000000 |
| ch06a | 12227 | 0.8699999999999999955591 | 4.070000000000000284217 | 2.8700000000000001065814 | 4.000000000000000000 | 4.000000000000000000 |
| ch06b | 12227 | 0.8699999999999999955591 | 1.290000000000000035527 | 0.5200000000000000177636 | 1.000000000000000000 | 1.000000000000000000 |
| pt02b | 31684 | 0.6700000000000000399680 | 42.990000000000001989520 | 9.5399999999999991473487 | 42.000000000000000000 | 13.000000000000000000 |
| ch03 | 0 | 1.0000000000000000000000 | 1.500000000000000000000 | 0.5000000000000000000000 | 1.000000000000000000 | 1.000000000000000000 |
| hh07a | 0 | 1.0000000000000000000000 | 2.180000000000000159872 | 0.4600000000000000199840 | 2.000000000000000000 | 0.000000000000000000 |
| pt01b | 14342 | 0.8499999999999999777955 | 36.049999999999997157829 | 7.9400000000000003907985 | 35.000000000000000000 | 10.000000000000000000 |
| ch04a | 0 | 1.0000000000000000000000 | 1.040000000000000035527 | 0.2300000000000000099920 | 1.000000000000000000 | 0.000000000000000000 |
| MPLBoth | 7314 | 0.9200000000000000399680 | 0.289999999999999980016 | 0.4500000000000000111022 | 0.000000000000000000 | 1.000000000000000000 |
| HHWeightProvided | 0 | 1.0000000000000000000000 | 3105.789999999999963620212 | 3794.8699999999998908606358 | 2112.119999999999890861 | 3342.590000000000145519 |
It is important to see that if one does not specify correctly the variable type, then skim() will not pick that up. The school type, ch03, is being recognized as a continuous variable instead of a categorical variable. Therefore, one should make sure beforehand that the variables are in their correct type to ensure correct variable summaries. Next, we define the levels of measurement of the variables in our data. This will help us know the correct data type to assign to each variable.
7.2 Levels of measurement
Any variable is composed of two or more categories or attributes. Thus the child’s gender is a variable with the categories male and female, country of birth is a variable with the categories being particular countries. The level of measurement of variables refers to how the categories of the variable relate to one another. There are three main levels of measurement: continuous, ordinal and categorical. Three characteristics of the categories of a variable determine its level of measurement:
- whether there are different categories;
- whether the categories can be rank ordered;
- whether the differences or intervals between each category can be specified in a meaningful numerical sense.
7.2.1 Continuous level
A continuous variable is one in which the categories can be ranked from low to high in some meaningful way. In addition to ordering the categories from low to high it is possible to specify the amount of difference between the categories or values. The child’s age, when measured in years, is an example of a continuous variable. We rank-order the categories of age (in years) from youngest (lowest) to oldest (highest). Furthermore, we can specify the amount of difference between the categories. The difference between the category “9 years old” and the category “13 years old” is 4 years. Other examples would be the number of household members, time taken to complete the numeracy assessment, and the numeracy score of the child.
We use the 5-number summary (box plot can also suffice) and a histogram to describe the distribution of continuous variables. In our current data, we only have the parent’s age and child’s age as continuous variables.
| Name | select(dat, ch02, pt02b, … |
| Number of rows | 96452 |
| Number of columns | 3 |
| _______________________ | |
| Column type frequency: | |
| numeric | 3 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| ch02 | 0 | 1.0000000000000000000000 | 10.00000000000000000000 | 3.250000000000000000000 | 5 | 7 | 10 | 13 | 16 | ▇▆▆▅▅ |
| pt02b | 31684 | 0.6700000000000000399680 | 42.99000000000000198952 | 9.539999999999999147349 | 18 | 36 | 42 | 49 | 80 | ▂▇▆▂▁ |
| pt01b | 14342 | 0.8499999999999999777955 | 36.04999999999999715783 | 7.940000000000000390799 | 18 | 30 | 35 | 40 | 80 | ▅▇▂▁▁ |
The typical age in years the children belong is \(10\) years old, while it is \(36\) and \(43\) years old for the mother and father respectively. The child’s age is spread fairly evenly across the age categories relative to both the mother and father’s ages (see the standard deviation). If one had to order the children by age from the youngest (\(5\)) to the oldest (\(16\)), then the middle child would be \(10\) years old.
Now, let us assess whether the categories of each variable tend to cluster towards the low or the high end. And possibly identify the potential outliers.
# Histograms and box plot
## child's age
ggplot(dat, aes(x = ch02)) +
geom_histogram(
bins = 20,
aes(y = after_stat(count / sum(count) * 100)),
fill = "gold"
) +
labs(x = "Age (years)", y = "Percentage (%)",
title = "Child's age histogram with percentage") +
theme_bw()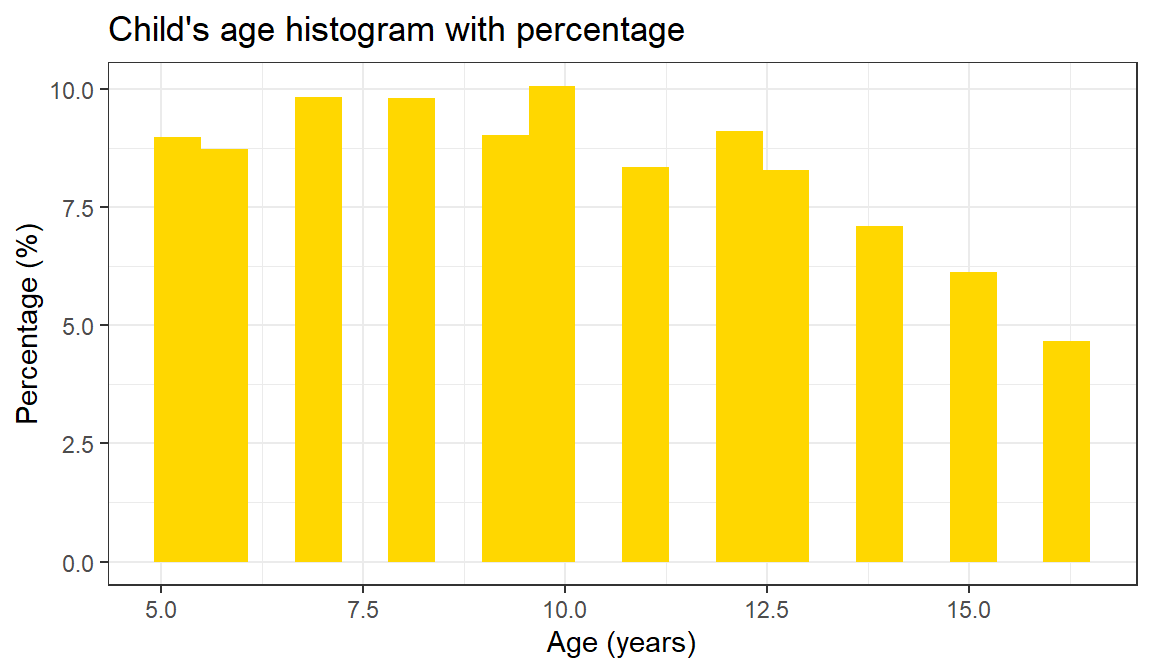
Figure 7.1: Distribution of child age in the ICAN-ICAR sample.
## father's age
ggplot(dat, aes(x = pt02b)) +
geom_histogram(
bins = 20,
aes(y = after_stat(count / sum(count) * 100)),
fill = "skyblue"
) +
labs(x = "Age (years)", y = "Percentage (%)",
title = "Father's age histogram with percentage") +
theme_bw()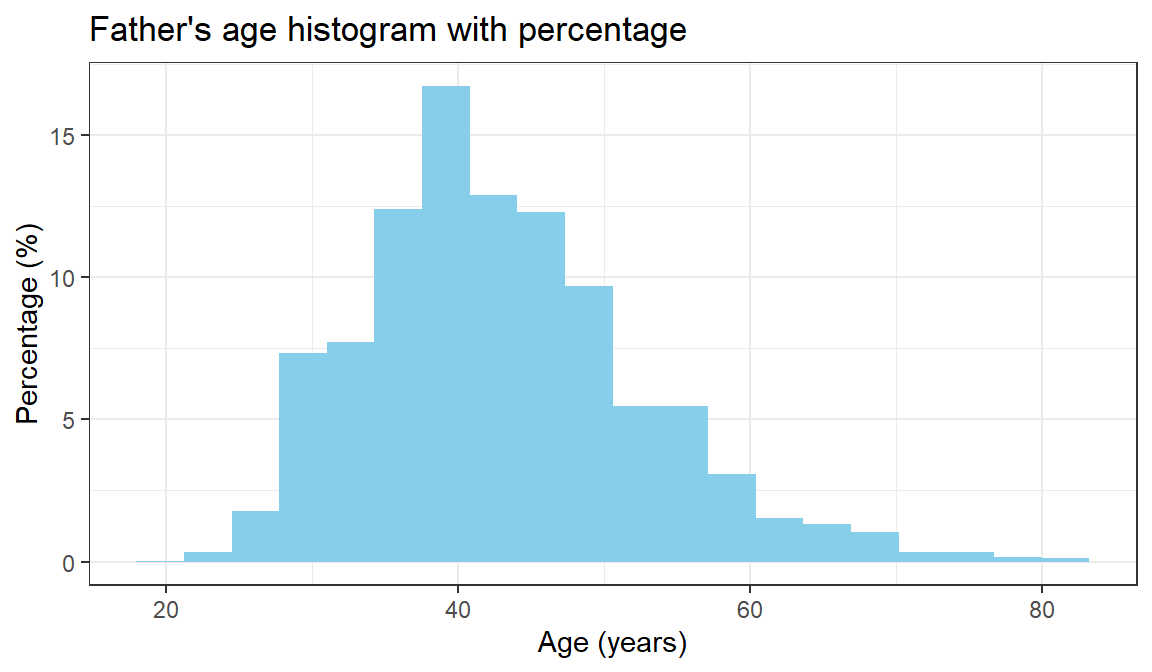
Figure 7.2: Distribution of child age in the ICAN-ICAR sample.
## mother's age
ggplot(dat, aes(x = pt01b)) +
geom_histogram(
bins = 20,
aes(y = after_stat(count / sum(count) * 100)),
fill = "magenta"
) +
labs(x = "Age (years)", y = "Percentage (%)",
title = "Mother's age histogram with percentage") +
theme_bw()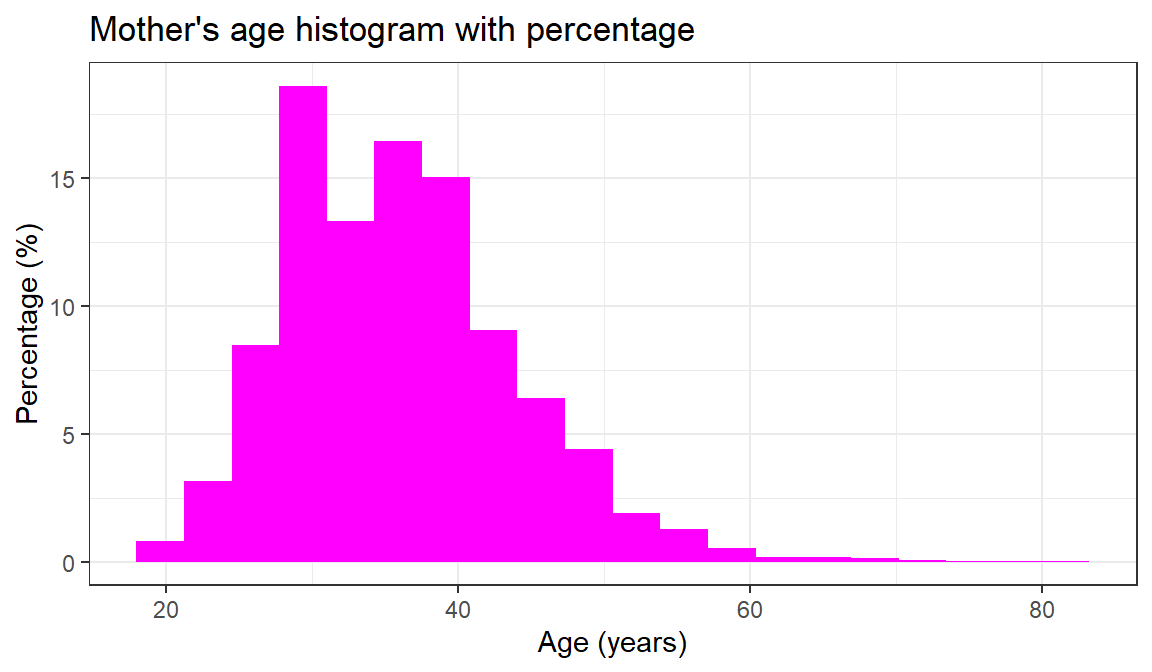
Figure 7.3: Distribution of child age in the ICAN-ICAR sample.
For the child’s age there is no evidence clustering - the variable is spread fairly evenly across the categories. Both the mother’s and father’s age cluster at the lower end of their respective distributions, with tails on the high end.
7.2.2 Ordinal level
An ordinal variable is one where we can rank-order categories from low to high. However, we cannot specify in numeric terms how much difference there is between the categories. For example, when the age variable has categories such as “child”, “adolescent”, “young adult”, “middle aged” and “elderly” the variable is measured at the ordinal level. The categories can be ordered from youngest to eldest but we cannot specify precisely the age gap between people in different categories. Measuring the child’s difficulty in their eyesight as “no difficulty”, “some difficulty”, and “a lot of difficulty” would produce an ordinal variable.
Typically, one can describe the distribution of an ordinal variable by asking about the frequency of children belonging to particular categories, asking which categories have a lot of cases and which have fewer cases. In that a frequency table will suffice.
Since the categories of ordinal variables can be ranked these categories should be put in their correct rank order in a frequency table. Failure to do so will distort both patterns in the data and statistics used to summarise them.
# first insert appropriate labels
dat = dat |>
mutate(
ch04a = as.character(ch04a),
ch04a = case_when(
ch04a == "1" ~ "No difficulty",
ch04a == "2" ~ "Some difficulty",
ch04a == "3" ~ "A lot of difficulty",
ch04a == "4" ~ "Cannot do at all",
TRUE ~ ch04a
)
)
# convert to ordered factor
dat = dat |>
mutate(
ch04a = factor(ch04a, levels = c("No difficulty",
"Some difficulty",
"A lot of difficulty",
"Cannot do at all"),
ordered = TRUE)
)Now, we are set to create a frequency table for the eyesight variable.
## # A tibble: 4 × 3
## ch04a n percent
## <ord> <int> <dbl>
## 1 No difficulty 93602 97.0
## 2 Some difficulty 2351 2.44
## 3 A lot of difficulty 342 0.355
## 4 Cannot do at all 157 0.163Pay attention to the description of ch04a - R recognizes it as an <ord> now. From the table, we can see that only \(2,95\%\) children in the sample have some form of difficulty in their eyesight, even after wearing glasses. One category in this variable accounts for the bulk of the cases. One can say that this sample is fairly homogeneous with regards to ch04a . In other words, the frequency table is not symmetrical because most of the cases are clustered at one end of a distribution of this ordinal variable. When cases are clustered at the low end the distribution is positively skewed.
Sometimes ordinal variables can often be displayed effectively with graphs. Now, we can going to show how ch04a is distributed using a bar graph.
dat |>
ggplot(aes(x = ch04a))+
geom_bar(fill = "violet")+
theme_bw() +
labs(title = "Vertical bar chart with counts",
x = "Eyesight")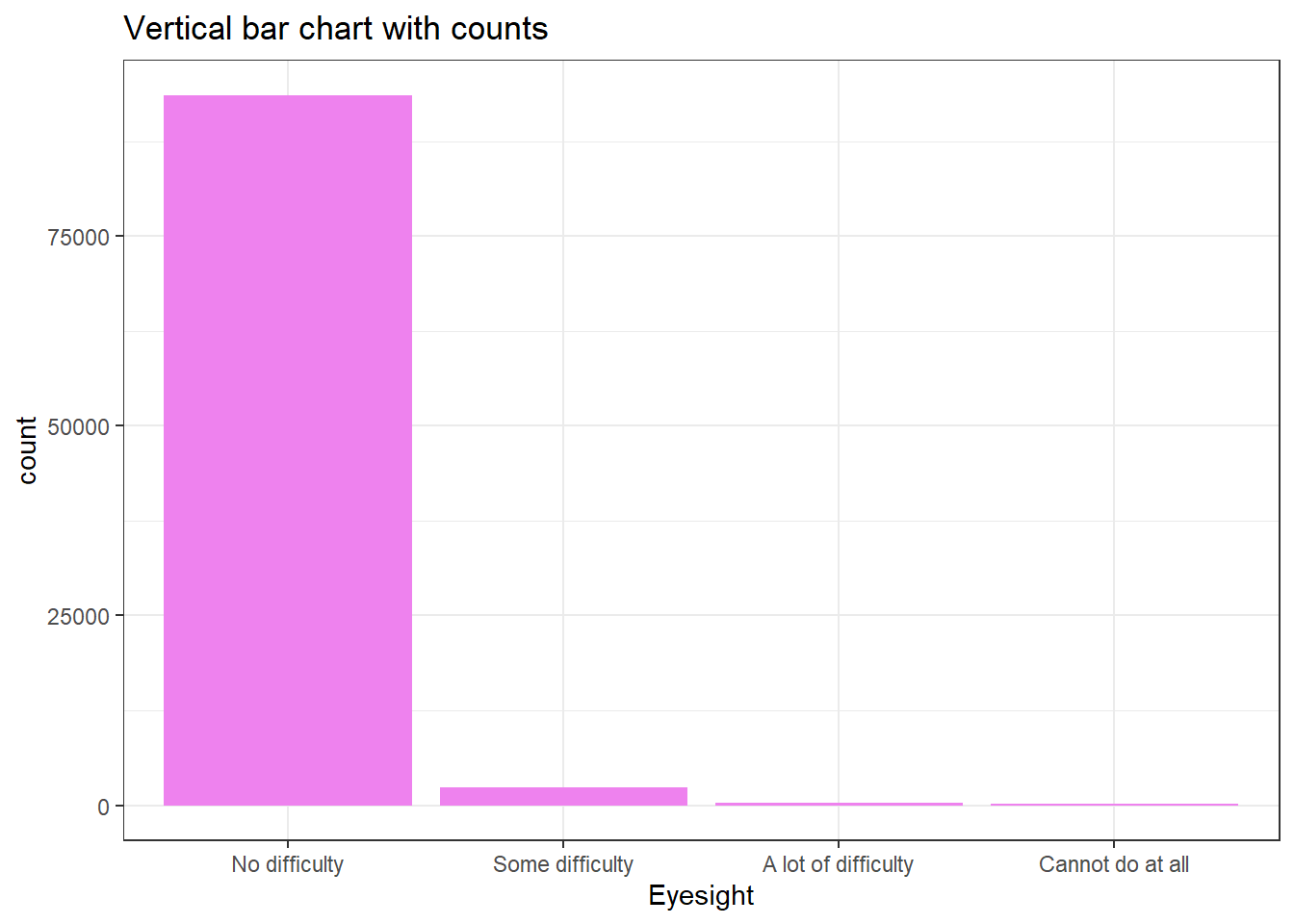 While the mode as a measure of central tendency can be for ordinal variables the median is preferred because it takes into account that children can be ranked on ordinal variables. The median is worked out by ranking each case in a distribution from low to high on the variable and finding the middle child. Whatever the category the middle child belongs to is the median category. In large scale survey research, this is done by obtaining a frequency table, as we have done above, for the variable and examining the cumulative percentage column. To locate the median simply look down this column until the cumulative percentage nudges over \(50\) percent and then look at the category of the variable that corresponds to this. In
While the mode as a measure of central tendency can be for ordinal variables the median is preferred because it takes into account that children can be ranked on ordinal variables. The median is worked out by ranking each case in a distribution from low to high on the variable and finding the middle child. Whatever the category the middle child belongs to is the median category. In large scale survey research, this is done by obtaining a frequency table, as we have done above, for the variable and examining the cumulative percentage column. To locate the median simply look down this column until the cumulative percentage nudges over \(50\) percent and then look at the category of the variable that corresponds to this. In ch04a case, the middle child is the one with no difficulty in eyesight.
7.2.3 Categorical level
A categorical variable is one where the different categories have no set rank-order. With a categorical variable it makes no sense to say that the categories can be ordered from low to high in some sense. The type of school the child goes to (ch06b) is a categorical variable where categories have no natural rank-order.
Two main types of summarising statistics are used for categorical variables to describe their distributions: those used to indicate typical values (central tendency), and those used to indicate group variation With categorical variables the only way to indicate the typical response is to identify the single most common response. The most common response, the one with the largest number of cases, is called the mode.
# firstly, give proper labels
dat = dat |>
mutate(
ch06b = as.character(ch06b),
ch06b = case_when(
ch06b == "1" ~ "Government",
ch06b == "2" ~ "Private",
ch06b == "3" ~ "Other",
TRUE ~ ch06b
)
)
# create a frequency table
dat |>
count(ch06b) |>
mutate(percent = 100*(n/sum(n)))## # A tibble: 4 × 3
## ch06b n percent
## <chr> <int> <dbl>
## 1 Government 62862 65.2
## 2 Other 2769 2.87
## 3 Private 18594 19.3
## 4 <NA> 12227 12.7In the table above, the single most common response is “Government”, thus “Government” schools is the mode of the ch04a. But, sometimes using the mode to measure the typical response is problematic. Picking the most common response does not tell us how typical it is. In that case, we have to provide a way of summarizing how diverse a group is. For categorical variables the appropriate measure of variation is the variation ratio. It is easily calculated by seeing what percentage of children are not in the model category. The variation ratio is normally expressed as a proportion. This is simply done by moving the decimal place on the percentage figure (percent not in modal category) two places to the left. Thus in the frequency table, the mode is “Government” which contains \(66,2\%\) of the sample. The percentage not in the model category is therefore \(33.8\%\). The variation ratio therefore is \(0,33\).
It is desirable to use a measure of variation alongside a measure of central tendency. The measure of central tendency gives us an idea of what is typical while the measure of variation gives us a sense og how typical typical is. The more variation there is in a sample the less well the average summarizes the sample. In the case of the variation ratio - the higher the variation ratio the more poorly the mode summarizes the overall distribution of the categorical variable.
A bar chart is most appropriate graphical tool one can use to describe the distribution of a categorical variable.
dat |>
ggplot(aes(x = ch06b))+
geom_bar(
aes(y = after_stat(count / sum(count) * 100)),
fill = "violet"
) +
coord_flip() +
theme_bw() +
labs(title = "Horizontal bar chart with counts",
x= " ",
y= "School Type")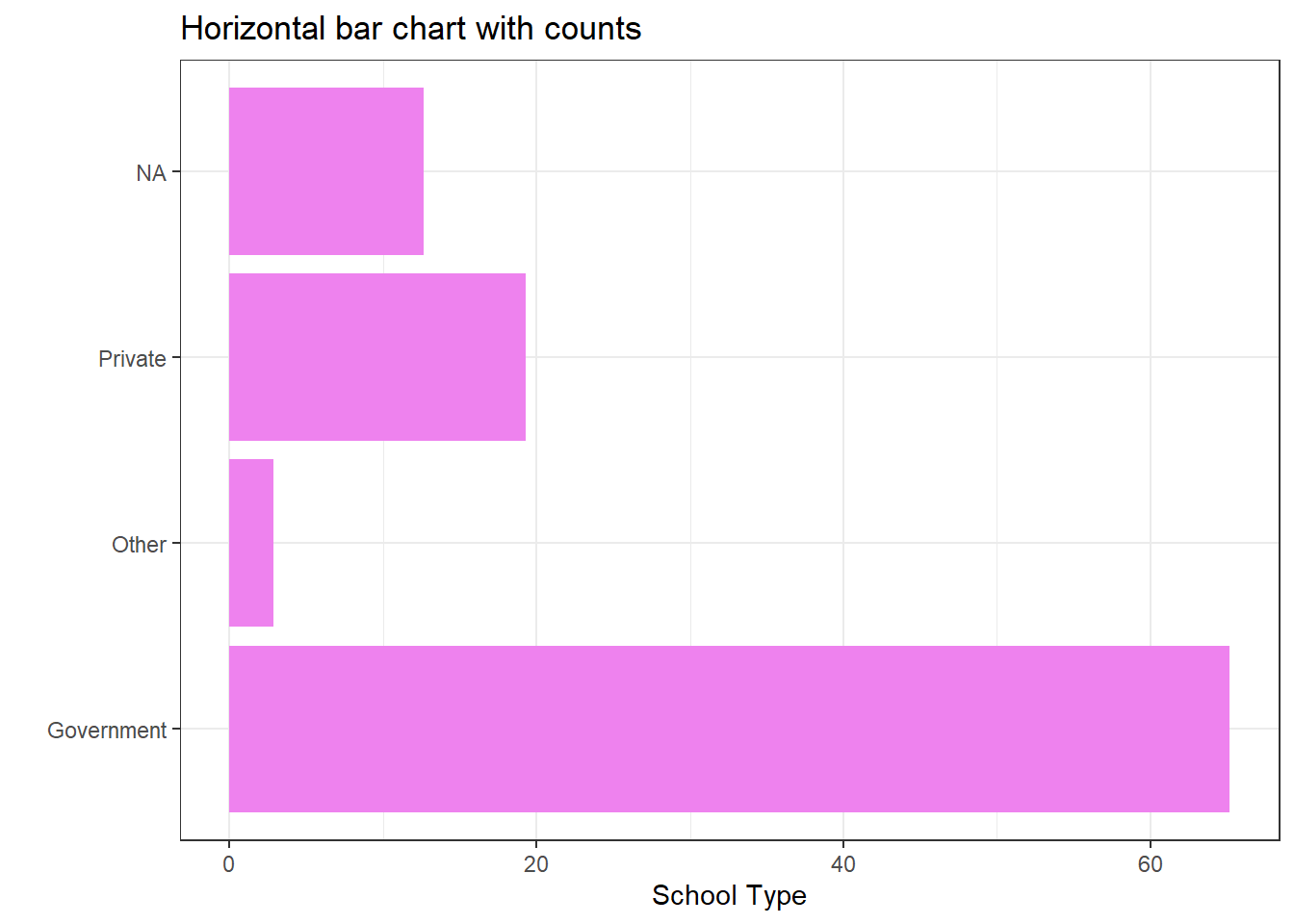 The table below summarises the graphical representation that can be used to describe variables at each of the three levels of measurement. Consider these everytime.
The table below summarises the graphical representation that can be used to describe variables at each of the three levels of measurement. Consider these everytime.
| Graph type | Categorical | Ordinal | Continuous |
|---|---|---|---|
| Bar charts | ✓ | ✓ | ? |
| Line graphs | ✗ | ? | ✓ |
| Area graph | ✗ | ? | ✓ |
| Histogram | ✗ | ✗ | ✓ |
| Boxplot | ✗ | ✓ | ✓ |
| Pie chart | ✓ | ✓ | ? |
Also, the table below helps one to choose summary descriptive statistics for different levels of measurement
| Category | Statistic | Categorical | Ordinal | Continuous |
|---|---|---|---|---|
| Averages | Mode | ✓ | ? | ? |
| Median | ✗ | ✓ | ? | |
| Mean | ✗ | ✗ | ✓ | |
| Dispersion/variation | Variation ratio | ✓ | ? | ? |
| Interquartile range | ✗ | ✓ | ? | |
| Variance/standard deviation | ✗ | ✗ | ✓ | |
| Symmetry | Graph/visual | ✗ | ✓ | ✓ |
| Skewness statistic | ✗ | ✗ | ✓ | |
| Kurtosis | Graph/visual | ✗ | ✓ | ✓ |
| Kurtosis statistic | ✗ | ✗ | ✓ |
7.3 Weighted summaries using the survey design
Unweighted summaries describe the sample. To describe the population, you must account for weights, clustering, and stratification.
We create a survey design object using the same structure used elsewhere in the course.
options(
survey.lonely.psu = "adjust",
survey.adjust.domain.lonely = TRUE
)
des_child_all = svydesign(
ids = ~interaction(CountryName, VillageID) + HHID,
strata = ~interaction(CountryName, TierOneUnit),
weights = ~HHWeightProvided,
data = dat,
nest = TRUE
)7.3.1 Weighted proportions and means
A weighted proportion of girls in the population:
## mean SE
## I(ch03 == 1)FALSE 0.51837382456526859276 0.0031900000000000001271
## I(ch03 == 1)TRUE 0.48162617543473146275 0.0031900000000000001271Weighted means for several continuous variables:
## mean SE
## ch02 9.8906230846134697288 0.029749999999999998668
## pt02b 41.4489833960381446332 0.115239999999999995217
## pt01b 35.6045036562518433243 0.0976400000000000045657.4 Household-level variables in a child-level file
When a household-level variable repeats across children, a child-level frequency table over-weights large households. A simple fix is to keep one record per household.
dat = dat |>
arrange(HHID, ChildID) |>
group_by(HHID) |>
mutate(hh_first = row_number() == 1) |>
ungroup()For example, compare a child-level and household-level distribution of roof type (hh07a), if that variable is available in your extract.
# child-level distribution (counts children)
dat |>
count(hh07a) |>
mutate(percent = 100 * n / sum(n))
# household-level distribution (counts households once)
dat |>
filter(hh_first) |>
count(hh07a) |>
mutate(percent = 100 * n / sum(n))To produce a weighted household-level distribution, subset the survey design to one row per household.
options(
survey.lonely.psu = "adjust",
survey.adjust.domain.lonely = TRUE
)
des_child_all = svydesign(
ids = ~interaction(CountryName, VillageID) + HHID,
strata = ~interaction(CountryName, TierOneUnit),
weights = ~HHWeightProvided,
data = dat,
nest = TRUE
)
des_household = subset(des_child_all, hh_first)
roof_w = svytable(~hh07a, des_household)
tibble(
roof_type = names(roof_w),
percent = as.numeric(100 * prop.table(roof_w))
)7.5 Missing data and skip patterns
Missing values are common in survey data. In ICAN-ICAR, missingness often reflects skip patterns. For example, grade (ch06a) is usually recorded only for learners who are currently enrolled.
Start by checking how much is missing.
dat |>
summarise(
total = n(),
missing_ch06a = sum(is.na(ch06a)),
missing_pct = 100 * sum(is.na(ch06a)) / n()
)## # A tibble: 1 × 3
## total missing_ch06a missing_pct
## <int> <int> <dbl>
## 1 96452 12227 12.7Then evaluate whether missingness aligns with enrolment status.
dat |>
group_by(EnrolmentStatus) |>
summarise(
total = n(),
missing_ch06a = sum(is.na(ch06a)),
missing_pct = 100 * sum(is.na(ch06a)) / n()
) |>
arrange(desc(total))## # A tibble: 3 × 4
## EnrolmentStatus total missing_ch06a missing_pct
## <chr> <int> <int> <dbl>
## 1 Currently Enrolled 84396 171 0.203
## 2 Never Enrolled 9403 9403 100
## 3 Out of School 2653 2653 100You can also estimate weighted missingness rates by subgroup.
## EnrolmentStatus I(is.na(ch06a))FALSE I(is.na(ch06a))TRUE se.I(is.na(ch06a))FALSE
## Currently Enrolled Currently Enrolled 0.9992557009928674238708 0.0007442990071324390860541 9.968166266869106224673e-05
## Never Enrolled Never Enrolled 0.0000000000000000000000 1.0000000000000000000000000 0.000000000000000000000e+00
## Out of School Out of School 0.0000000000000000000000 1.0000000000000000000000000 0.000000000000000000000e+00
## se.I(is.na(ch06a))TRUE
## Currently Enrolled 9.968166266869084540629e-05
## Never Enrolled 0.000000000000000000000e+00
## Out of School 0.000000000000000000000e+007.6 Practice Exercise
Use the ICAN-ICAR data and the tools in this chapter to answer the questions below.
- What proportion of the sample is rural (
Location == "Rural")? Compute both the unweighted and weighted estimate. - What is the unweighted and weighted mean child age (
ch02) for enrolled learners (enr_status == "Currently Enrolled")? - Create an age group variable (for example,
<= 10vs> 10). What share of learners falls in each age group? - Produce a weighted frequency table for
Locationwithin one country of your choice. - Investigate missingness in
ch06abyresidenceand bysex. Report the results as unweighted and weighted proportions.